
















谈谈AutoML、辛普森悖论、以及未来机器学习工程师的价值
我是EYS的张森。自由职业工程师,现在在这里搞人工智能。目前集中的领域是混音(Mixing)和母带(Mastering)。最近工作和学习的过程中,对算法、模型以及数据有些感触,结合最近的一些新闻谈谈这方面的事情吧。
在最近的谷歌技术峰会上出现了很多关于AutoML的报告,在一些数据预测以及图像识别技术上,用AutoML制作的模型于性能上超过了职业机器学习工程师所制作的模型。于是有人这样调侃,说不定首先被人工智能抢走饭碗的是人工智能工程师自己呢。
AutoML,顾名思义,就是你把数据准备好,然后系统自动帮你寻找最佳的模型。模型设计往往同时要求数学知识和相关的经验与直觉,这就使模型设计往往受制于设计者的知识和理解。而AutoML能通过各种算法,在广范围的模型和处理方式中寻找最佳的组合方式,所以在一些任务中超过机器学习工程师是很自然的。
从实际的技术角度来讲,现在的AutoML的限制还很多:比如说无法下载模型和代码来抽取中间特征,这就导致用户只能用它来做一些单纯的任务,无法组合下一个流程进一步完成现实世界的更复杂的任务;比如说计算成本很高;比如说出现问题时不易调查等等。现阶段来说,AutoML不要说代替机器学习工程师,恐怕连简单的应用都存在很多障碍。
然而技术在进步,这里面的很多问题是可以解决的。
这里,我们且把眼前的这些问题放下来,谈一谈更本质的事情:假如未来AutoML可以完成构筑模型时的大部分任务,那时机器学习工程师干啥?
在吴恩达(Andrew Ng)访谈杰弗里·辛顿(Geoffrey Everest Hinton)的对话里,辛顿的一段话给我的印象很深。
“Our relationship to computers is changed. Instead of programming them, we now show them.”
(我们与计算机的关系已经变了。重要的不再是指示它们去做什么,而是给它们学什么。)
在今天,说到人工智能工程师,很多人首先大概会联想到算法、模型和框架等等。这些东西确实在不断地被自动化,你花费很大成本去开发的东西,往往没几个月,就有现成可用的东西公开面世了。辛顿再此指出的“给它们学什么”则更偏重于“设计用什么数据和做什么事情”。比如说相对于如何在Kaggle竞赛中胜出,更注重如何在Kaggle出好题。
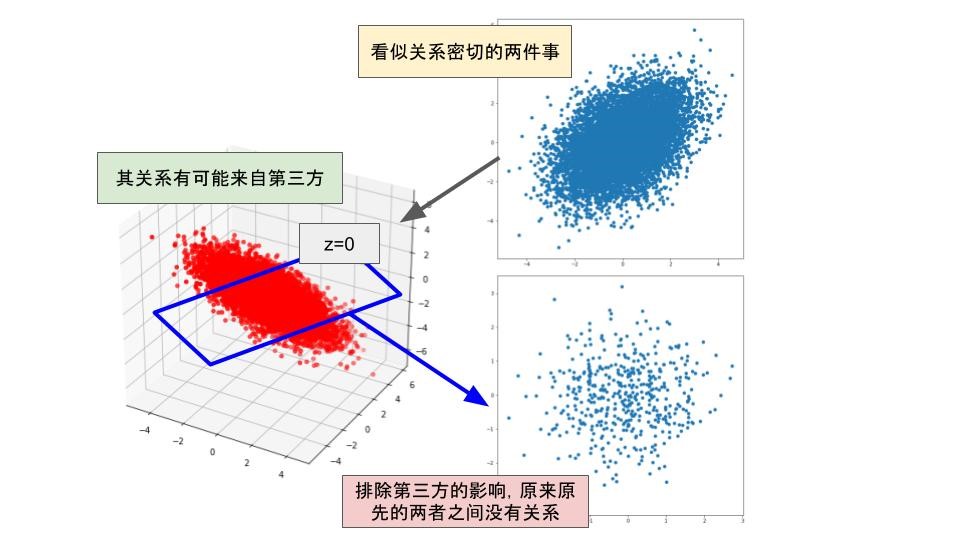
我认为辛普森悖论的例子最能体现机器学习工程师的本质价值之所在。曾经,有人调查了1973年美国加利佛尼亚大学的研究生的录取情况,发现男性的录取率为44%,而女性的录取率却只有35%。看到这里,很多人或许会惊叹,堂堂世界排名前十的学校在录取学生的时候竟然存在性别歧视?!那么,究竟哪些学部歧视情况最为严重呢?又有人调查了各个学部的录取情况,结果,竟然没有一个学部录取新生时存在明显的男女性差。那么整体的性差是哪里来的呢?原来每个学部的录取率不同,而女性似乎偏向于志愿那些门槛高的学部,其结果就导致了虽然录取过程并不存在性歧视,但只看整体平均值的话,好像性歧视现象很严重一样。
辛普森悖论给我们的一个重要的启示是,我们永远无法客观判断自己手中的数据是否足以得出结论。所以不可以过度相信模型,在处理数据的时候,不能仅看精度好坏,更需要去注意数据背后的现象。最有,我们以一些笑话结尾吧:
- 人口与学校数量成比例。犯罪人数与人口成比例。于是犯罪人数与学校数量成比例。不考虑人口因素只看犯罪人数和学校数量的话,会得出结论:学校教唆人们犯罪。
- 一个国家发生瘟疫。国王派人调查。报告显示,重灾区医生的人数比别的地方多很多。于是国王决定赶走所有的医生。
- 经济下滑导致失业,失业诱使自杀。很多国家在经济下滑时期为了缓解压力,增加对公益的投资。如果不看经济状态的话,数据或许会告诉你:投资公益导致人们自杀。
- ……
早崎 翔大
Share
